

Helping leaders practice the conversations that are hardest to get right
Coach the Mountain — AI Enabled Leadership Coaching Simulator
Project Context: I built this as part of Lovable's SheBuilds challenge for International Women's Day. There As someone who has been around so many incredible women who are great leaders, I wanted to build something that helps women, or anyone really, continue to build their leadership skills. Giving feedback, addressing a performance gap, navigating conflict, these are conversations most leaders never get to practice before they actually need them.
One thing to know going in: this is meant for practicing language and framing, not for replacing the real conversation. Depending on how complex or high-stakes a conversation is, sometimes the right call is to have it face to face instead of over chat, and figuring that out is part of the skill too. What exists today is the simulation and evaluation layer.
The fuller vision includes a foundational tier, Base, focused on practicing SBI and GROW through prompts and reflection before stepping into a full conversation.
My role: Instructional Designer, Conversation Designer, Prompt Engineer, Product Tester
Tools: Lovable (build and engineering), Claude (thought partner for framework design and persona refinement)
Results:
Built a fully functional leadership coaching simulator in roughly a day, including iterative testing and refinement
Designed four difficulty tiers using a ski trail metaphor, mapping conversation types to stakes and complexity
Implemented a combined SBI and GROW frameworks with real-time phase detection and a 5-criteria evaluation system
Caught and resolved a trigger-matching bug through hands-on testing that was overriding specific coaching responses with generic ones
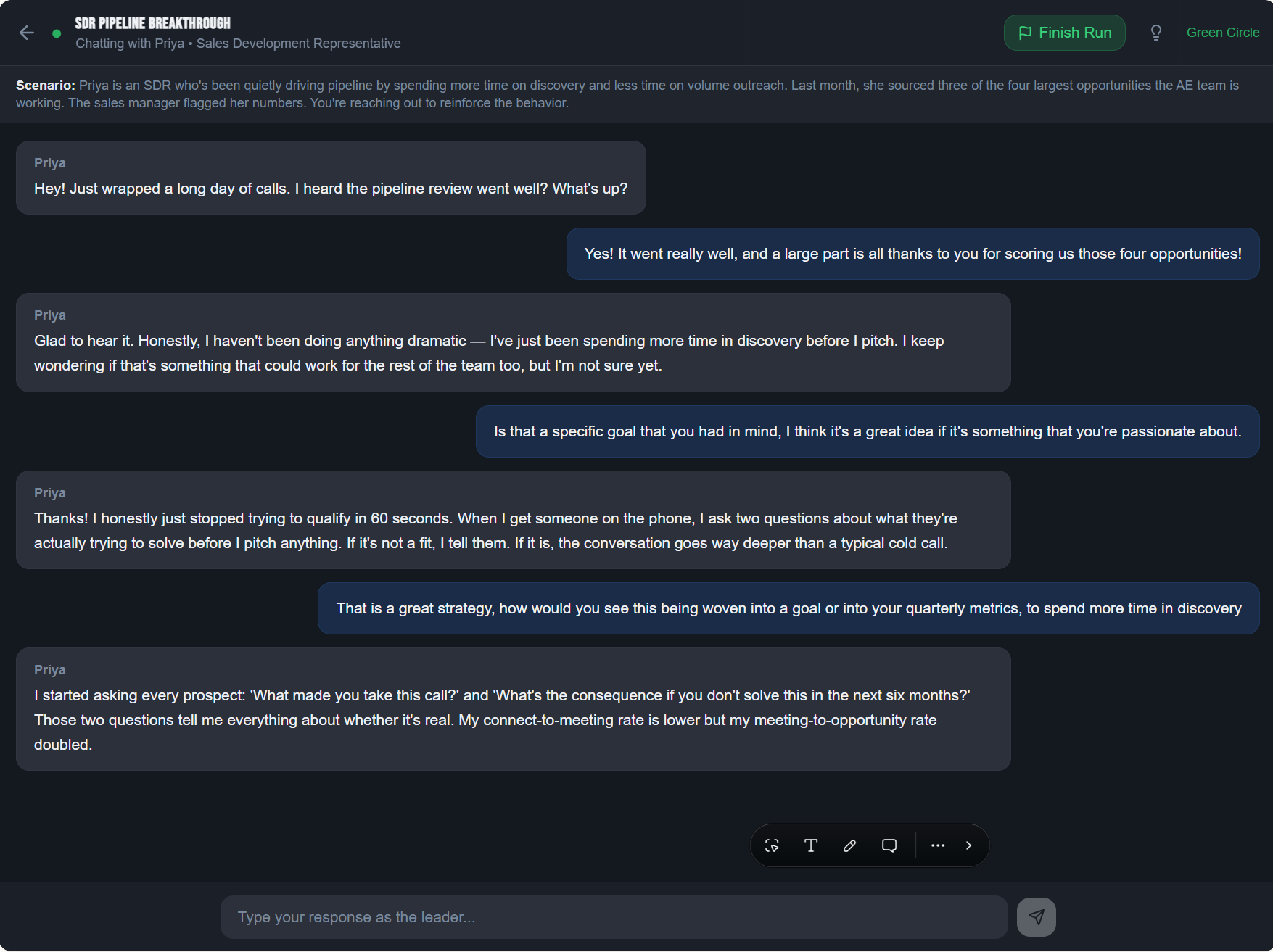
Two coaching frameworks, one seamless conversation, mapped as ski trails
The app combines two established coaching models into a single conversational arc: SBI to frame the conversation, GROW to coach forward from there.
Step 1: Frame, using SBI
Most coaching conversations start because of something specific, a missed deadline, a tone in a meeting, a standout presentation. SBI gives the leader language to name it clearly:
Situation — when and where it happened
Behavior — the specific, observable action, not a character judgment
Impact — the effect on the team, the work, or trust
This grounds the conversation in something concrete and shared before moving forward.
Step 2: Coach, using GROW
Once the behavior and its impact are on the table, GROW shapes where the conversation goes next:
Goal — what does this person want, in this conversation, this quarter, their career
Reality — what is actually going on, workload, blockers, dynamics
Options — what could we try, weighing trade-offs together
Way Forward — what are we committing to, who does what, and how we follow up
Live in the sidebar
A Coaching Guide panel tracks this in real time, following the leader's messages through the full arc, S, B, I, then G, R, O, W, highlighting the current phase with example prompts at each step.
To make the stakes of each conversation intuitive, four scenario categories map to ski trail difficulty ratings:
Green Circle — Wins and team recognition. Reinforcing what is working.
Blue Square — Operations and process coaching. Sharpening workflows and execution.
Black Diamond — Performance and behavior gaps. Addressing missed expectations.
Double Black Diamond — High-stakes situations and team conflict. Navigating incidents, escalations, and attrition.
But difficulty is relative. Even a Green Circle conversation can feel overwhelming depending on where someone is in their skillset, while for someone else it might be a conversation they could have in their sleep. The trails are not a universal scale, they are a starting point for figuring out where you actually need the practice.
Finishing the run
When a conversation wraps up, the leader can "finish the run" and get a coaching evaluation, like reviewing a run with an instructor after coming down the mountain.
The evaluation includes an overall score out of 10, plus a breakdown across five criteria:
Empathy & Active Listening
SBI Framework Usage
GROW Model Application
Psychological Safety
Actionable Outcomes
What makes this useful is that the feedback references the actual conversation, not a generic rubric. In one test run, a leader gestured at an issue ("survey scores," "not being perceived well") without naming the specific behavior or its impact, scoring SBI usage at 4/10. The evaluation pointed out exactly what was missing, including a detail from the scenario itself that never made it into the conversation.
This is still very much a work in progress. I am running a lot of conversational tests right now, and getting this right in practice would take more conversational prompting and tighter parameters than a demo allows.
Preview of the feedback that someone can get based on the five criteria.
Testing the run, and finding the cracks
The first version of the app could hold a coaching conversation, but it was not quite right yet.
What I found and fixed:
Generic responses overriding specific ones. When I asked for deeper dialogue, a bug surfaced where generic keyword triggers were overriding more specific coaching triggers, producing flat replies when something more specific was warranted.
Wrap-ups not recognized. When a leader clearly closed a conversation ("let's schedule time to follow up"), the simulated employee would sometimes ignore that and push another challenge question instead of acknowledging it.
Accessibility on the results screen. Progress bars were overlapping the score numbers, making them hard to read.
Tone of feedback. Low scores originally led with a raw number. I updated the evaluator to lead with constructive, score-aware framing, the same Psychological Safety principle the tool evaluates leaders on.
What I am working on right now:
Making every persona actually responsive. I am adding a layer so the simulated employee processes and replies to what the leader actually said, in character, rather than relying on trigger-matched templates as the primary mechanism. Templates and defaults become fallbacks, not the main event.
Testing across all four personas per run. Each "run" has four different conversations, and I am working through the conversation flow for each.
Cleaning up the History screen UI. I need to make some adjustments for some overlapping issues. I also need to run a deeper accessibility check.
Creating QA/QC Agents. to help expedite a review process by also checking the quality.
Finalizing feedback rubric. I want to make sure that the feedback to a person provides quality and is actionable for them.
These fixes address real issues, but they also point at something bigger: running the same scenario with different leadership approaches should produce different responses. That is the next layer, the kind of conversational prompting and parameter tuning that goes beyond a demo and into a tool people would actually rely on for repeated practice.
What’s Next?
Base, a foundational tier before the simulation. Right now, the assumption is that someone already has grounding in GROW and SBI, this is where they apply it. But applying a framework fluidly in a live, emotionally charged conversation is a big leap from understanding it on paper. Base would close that gap, prompts and reflection questions focused purely on the frameworks themselves, no simulated conversation yet, so someone can build confidence with the mechanics before stepping onto a trail with another person in the room. It is the bunny slope before the chairlift.
A few smaller refinements within the simulation:
Persona and scenario tailoring — choosing which of the four personas and conversation types are most relevant to a person's actual development needs
An exit prompt — if someone leaves mid-conversation, a choice to finish for feedback or simply clear the session
Formative, inline feedback — surfaced during the conversation, not just in the summary afterward
The bigger picture: connecting practice to real development. Right now this is a standalone simulator (an a concept piece), but the natural next step would be integration with an LMS/LCM or HCM tying practice sessions to a person's actual goals or performance conversations. Beyond that, an automation agent could pick up notes or context from a real 1:1 with a leader and surface relevant practice scenarios or reflection prompts afterward, closing the loop between rehearsal and the real conversation.
A note on scope: This is a concept demo, not a production tool, built to explore an idea quickly and test it hands-on. If this were ever something people actually used, it would need security hardening and a lot more testing beyond what a weekend build allows. That is intentionally out of scope here. The point was testing the idea, not shipping a product.
Where this sits, and why that matters
In evaluation terms, this sits at what Will Thalheimer's LTEM model calls Decision-Making Competence, a step beyond knowledge checks, but short of measuring real on-the-job behavior change, Kirkpatrick's L3. That gap, between rehearsing a decision and actually doing it differently with a real person, is exactly what the LMS/LCM or HCM integration idea above is reaching toward.
That gap is also the point. This tool does not pretend to be the conversation, it is the rehearsal before it. I did build this in a day, then tested by actually using it, and it still being refined, it is a small, honest example of how I think about learning design: start with the moment someone is trying to get better at something real, build something that helps them practice it, and be clear-eyed about what that practice can and cannot do on its own.